
The Essential Guide to Data
Data is complicated. Uncomplicate it — and realize all that value — with this free guide.

There’s a well-known 21st century claim that "data is the lifeblood of every organization." But there’s an unwritten caveat to this: data must be of good quality.
Today it's easier than ever to get data on almost anything. But that doesn’t mean that data is inherently good data, let alone information or knowledge that you can use. In many cases, bad data can be worse than no data. It can easily lead to false conclusions.
So, how do you know that your data is reliable and productive? This is what we call data quality.
In this article, we'll go over the core aspects of data quality and things to consider when working with data quality. Then, we’ll move into the practice of data quality management.
Before we go into detail, remember that data quality is ultimately about common sense. It can be easy to get lost in numbers and metrics, but the core idea is simple:
Data quality is the term to use when you know that your data is giving you a full, accurate picture of the real world in a usable form.
On a more technical level, data quality is a measure of how well data serves the purpose it's intended for. While there are countless metrics to use to evaluate data quality quantitatively, we can categorize them into a few vital elements or "dimensions" of data quality (which we’ll detail shortly):
Each of these elements needs to be checked and managed with planning, rules, and metrics to ensure that data can be used properly without creating a false view of the situations it represents. This is why data quality is so important. Take these examples:
Data quality management needs to address all these possibilities and more in a complete and careful manner.
(Related reading: common data types & data management vs. data governance.)
Data is used in all industries today. Done well, data can be incredibly useful for:
However, it's vital to ensure that the data you're using reflects the real world and is genuinely usable — in many cases, the data may be inconclusive or not usable at all and for any number of reasons. Working with poor, low-quality data can lead to all sorts of bad outcomes and decisions. In an extreme situation, the death of a healthy organization.
We can understand how bad data can be disastrous. But ensuring high data quality is not easy.
For instance, any number of things can go wrong between accessing, processing, and distributing data. You can discover that your data sets are incomplete, inconsistent, and inaccurate, leaving you frustrated and at a loss in handling the data you're left to work with.
We can break data quality down into several core elements. One way to see into and better understand these elements is with data observability, which can power more efficient data pipelines and workflows.
We’ll use a simple example to illustrate these elements: You survey the ages of your customers to better understand who is using your product.
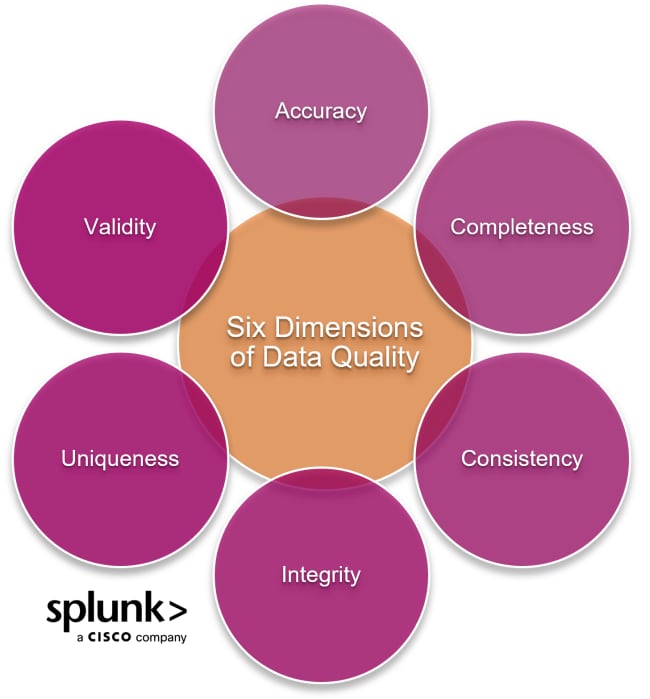
Does the data match the real world? Put simply, accuracy is the measure of whether the data is "correct" or not. For example, if customers lie about their age or make a typo, that data would not be accurate.
Completeness asks, Is all relevant data included? This is a vital aspect to address during data collection. For example, if parents fill out the survey, data on how many of your customers are children may be missing.
With consistency, you want to know: Is the data the same wherever we look at it?
Suppose you have two shops collecting this data. One enters ages as a word ("thirty-seven"), and the other as a number ("37"). If you then want to collect the data and do statistics, you'd have to reenter one data set or the other.
Data consistency refers to a standard format and data collection methodology that avoids this kind of conflict by looking at:
Data integrity asks, Does the data stay the same over time? Once you collect the survey data, you'll likely be using it for a while to process and gain value from it. If it is reentered at some stage, and certain records aren't entered, its data integrity is compromised.
Is each data point collected only once? If the same customer fills out the survey over and over, they skew the data toward their age bracket.
Finally, validity asks: Does the data make sense?
Data validity is similar to accuracy but instead refers to formatting and other aspects. For example, if an age is "3#", we can discard that data point because "#" is not a number.
With these six data quality dimensions, we can now look at a few concepts in more detail.
When learning about data quality, it's common to see data integrity listed as an aspect of data quality. However, when you look up data integrity, the information about it often lists the same aspects as data quality. Certain sources may even define data integrity as larger in scope than data quality.
This is because data integrity is, loosely put, data quality over time.
After we collect and handle data, it rarely sits around collecting dust. We use, process, and communicate data, often in several stages, across multiple entities, internal or external. Organizations or teams may…
With each of these steps, data quality can vary. One team might change the data format to suit their system, or they might altogether discard certain data points. However, data quality remains just as relevant no matter what happens to the data.
Data integrity covers the "resilience" of data quality. It often covers aspects of data protection and data security — how well the data is handled and preserved — as well as the quality of the original data.
That means: we can see integrity as part of data quality and vice versa. Data integrity deals with the same areas as mentioned above because these same areas are what need to be maintained during data-handling events.
Data quality management encompasses any practices and principles for maintaining data integrity, usefulness, and accuracy. These practices are enforced at different data lifecycle stages to ensure consistent data quality.
The success of a data quality management plan is measured through the lens of the six dimensions of data quality. You’ll set metrics to track those dimensions for each use case or project, as your data needs may vary.
Data quality management is sometimes likened to data management.
Importantly, in discussing DQM, understand that data quality is contextual. What counts as quality data in one scenario may be below the benchmark for another data use case. For instance, the data used in a survey about customer satisfaction will not be sufficient for creating a campaign to launch a new product or feature.
In essence, the ultimate check for data quality is not only accuracy — it’s the relevance of the data.
Here's an easy step-by-step process for implementing data quality management within your organization:
There's no better way to work towards improved data quality than looking at where the data journey begins: the data lifecycle.
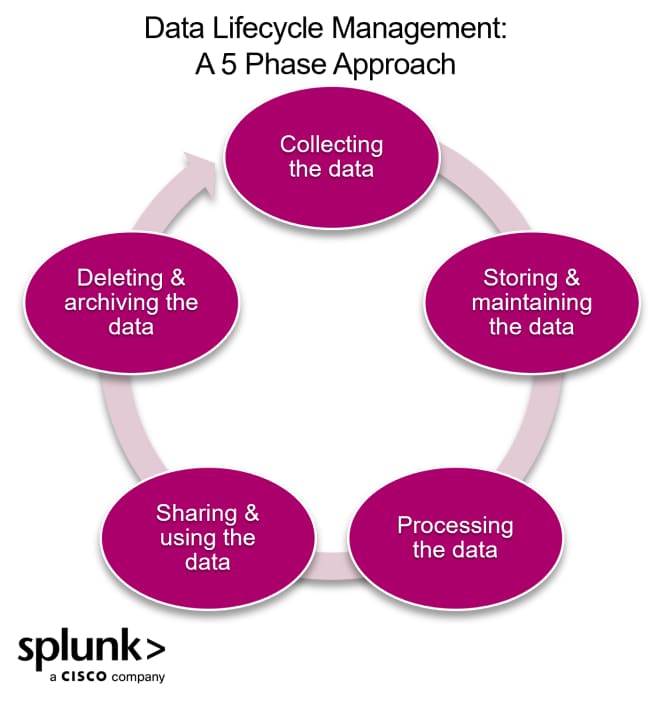
The most common and impactful data issues can be matched to a data lifecycle stage. For instance, incomplete data — the most common data quality problem — is traced to Steps 1 and 2 in the lifecycle: data collection and data storage. Doing this also nips data quality issues before they escalate.
You can take this step further by running a data quality assessment. That is, you can:
Doing this will provide a foundation for setting up the data quality management plan.
This step kicks off the real implementation of a data quality management plan. While the general metrics on data quality apply to organizations in different industries, you should have your own, specific criteria for data quality.
For example, in defining data accuracy on data sets, how much percentage of data error do you allow?
At this stage, you can develop a playbook for your data personnel to fall back on, which should include the following:
Even with the best tools, you still need qualified persons overseeing the data lifecycle and executing the data quality management strategy. Importantly, DQM will not work if it's implemented in a silo.
So, look for data professionals who can understand data across a variety of business use cases, applying appropriate data governance as needed. These professionals should be familiar with the data quality metrics and match them to the correct use case.
An excellent place to start for this is with a chief data officer. Other roles that can support here include a data quality manager, data analysts, data engineers, and even data scientists.
(Related reading: data science & analytics certifications to earn.)
Data quality management tools help identify data quality bottlenecks. Your tool of choice should be able to automate the following functions, which are necessary for upholding data quality:
Some tools that help with these are Atacama, Talend, Informatica, and Precisely Trillium.
(Related reading: top data analysis tools to use.)
After executing the data quality management plan, you'll still need data monitoring to observe the changes even after implementation. This will help you to:
Consider if the data conforms to the expectations and standards set for that data. Consider if data points make sense for the format and data type.
With the five-phase approach and these best practice, you’ll be well on your way to achieving and managing quality data.
Data lakes and data warehouses are two standard options for storing big data — but savvy data users know to use lakes and warehouses differently to maintain data integrity.
A zero-trust environment provides a hands-on approach to security concerns around data. It involves device monitoring and gatekeeping employee access to the organization's network.
Gaining visibility into how your organization's data is processed and the performance of your data pipeline can help you improve data quality, which is what data observability helps with. You'll be able to:
Use extract, transform, and load (ETL), a three-step data process for creating a standard and unified database free of errors and inconsistencies. Today, more data practices are turning to ELT —extract, load, then transform — which is faster and enables more flexibility.
Be selective in sourcing data: you do not need all the data you’ve gathered. Instead, focus on introducing insights relevant to your business or customers' needs—you can skip those trendy metrics unless they really add value.
To close this out, let’s share our favorite tip: Learn to view data quality as a combination of conceptual thought and objective evaluation.
See an error or have a suggestion? Please let us know by emailing splunkblogs@cisco.com.
This posting does not necessarily represent Splunk's position, strategies or opinion.


The world’s leading organizations rely on Splunk, a Cisco company, to continuously strengthen digital resilience with our unified security and observability platform, powered by industry-leading AI.
Our customers trust Splunk’s award-winning security and observability solutions to secure and improve the reliability of their complex digital environments, at any scale.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2025 Splunk LLC All rights reserved.
