
The State of Observability
Realize 2.67x returns on investments. See how in our latest State of Observability report.

Adaptive thresholding is a term used in computer science and — more specifically — across IT Service Intelligence (ITSI), for analyzing historical data to determine key performance indicators (KPIs) in your IT environment. Among other things, it’s used to govern KPI outliers in an effort to foster more meaningful and trusted performance monitoring alerts.
The thresholding method specifies the acceptable high and low values for the data produced by IT infrastructure, and is a crucial element of performance monitoring. ITSI offers two threshold types: static and adaptive. Static thresholds allow IT teams to use policies to select different static values for KPIs at different times of the day and week. Adaptive thresholding, on the other hand, uses machine learning to dynamically calculate time-dependent thresholds for these KPIs, allowing operations to more closely match alerts to the expected workload on an hour-by-hour basis.
Splunk IT Service Intelligence (ITSI) is an AIOps, analytics and IT management solution that helps teams predict incidents before they impact customers.

Using AI and machine learning, ITSI correlates data collected from monitoring sources and delivers a single live view of relevant IT and business services, reducing alert noise and proactively preventing outages.
Adaptive thresholding enables service status to be viewed along a gradient of normal to abnormal — rather than a binarization state of either working or broken. A service that reaches a critical threshold may warrant an alert, for example, but a high threshold — though concerning — probably would not. This more discerning approach reduces alert fatigue and helps IT teams direct their energies toward the most critical issues
.In the following sections, we’ll look at how adaptive thresholding works, how it’s used and various adaptive threshold methods, as well as why it should be an important part of your organization’s performance monitoring strategy.
Information Technology Service Intelligence (ITSI) refers to a software solution that uses machine learning to help IT managers monitor complex IT environments and manage analytics-driven IT operations.
ITSI tools are used to monitor and analyze network events to predict and prevent service disruptions. To do that, they rely on AI algorithms to identify patterns and trends in network activity that could result in service degradation or downtime if they’re not proactively corrected. By using an alert-based system, ITSI tools enable IT teams to take corrective action to prevent disruptions and outages.
ITSI tools generally employ a four-step process:
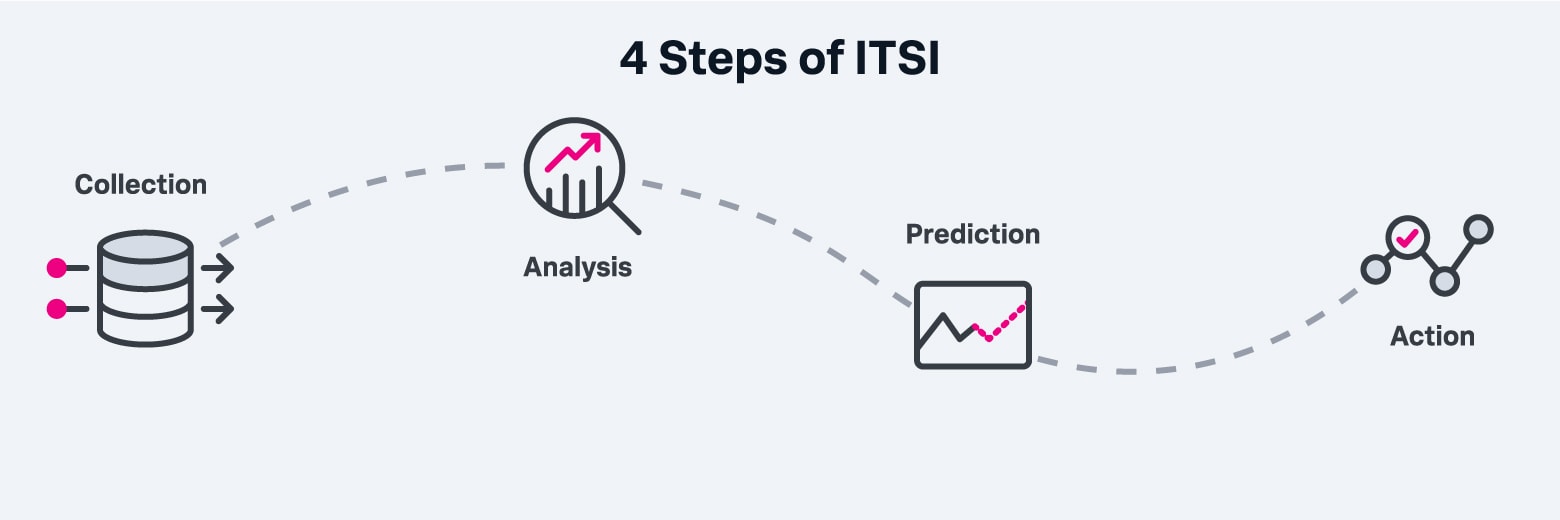
ITSI tools employ a four-step process that includes collection, analysis, prediction and action.
KPIs, or key performance indicators, are benchmarks by which the performance of a network and its components are measured. KPIs differ from metrics in that KPIs define an outcome, whereas metrics are data points that are used together to measure progress toward that outcome. For example, “reliability” is a common KPI that expresses the probability that a service will perform its required functions over a specific period of time. It’s calculated using two essential failure metrics: Mean Time to Repair (MTTR) and Mean Time Between Failures (MTBF).
While there’s no universal standard for what enterprise KPIs should monitor, the following are commonly used to assess the overall status of a service:
In ITSI, a KPI is saved as a search that returns the value of an IT performance metric, such as CPU load percentage, memory usage or response time. Each KPI is associated with a specific service, which allows you to use KPI search result values to monitor service health, check the status of IT components, and troubleshoot trends that might indicate an issue with your IT systems.
KPIs can be used together to determine the overall health and performance of your IT environment, and ultimately help measure progress toward various objectives and goals. Specifically, KPIs can help with:
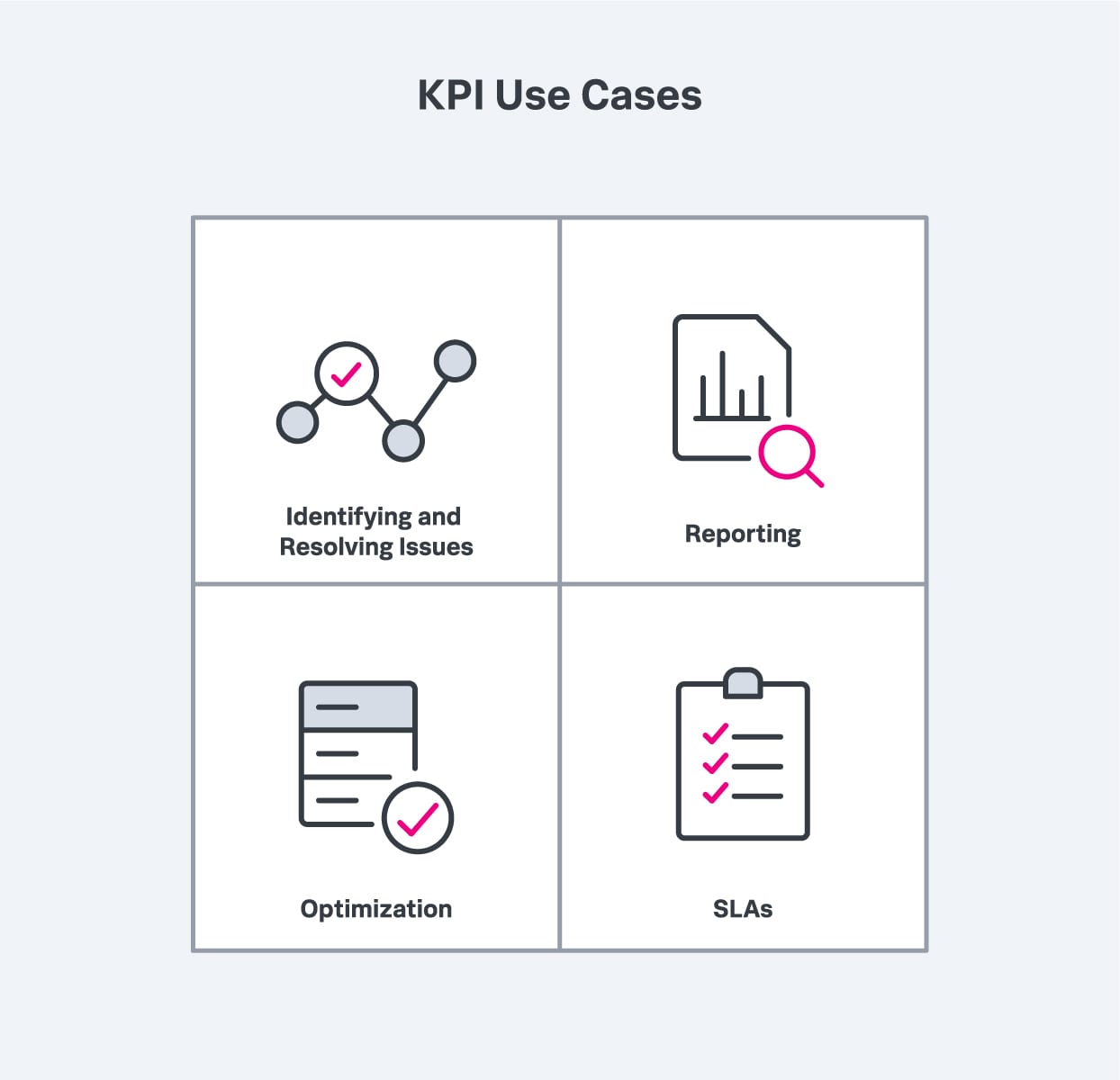
KPIs can be used to identify and resolve issues, report on performance trends, improve performance and ensure that SLA performance standards are being met.
Adaptive thresholding works by using machine learning techniques to analyze historical data, sometimes displayed in a histogram, for patterns that help define the normal state of your environment. You configure different threshold values, or intensity values, to determine the current status of any particular KPI to then drive more meaningful alerts. The simplest form of global thresholding is binary thresholding, or thresh_binary, which applies to an either/or outcome. But most thresholding is applied on a grayscale.
To better understand how this process works, you need to familiarize yourself with a few ITSI concepts — like service health scores, KPIs, and dependent services (sometimes called subservices):
These concepts are designed as a hierarchy. Each service in your environment receives a health score that is calculated based on the status of the KPIs and subservices you define for that service, known as an adaptive_thresh_mean_c. Every KPI requires a threshold configuration. ITSI, which continuously monitors KPI statuses and health scores, allows for six different severities — normal, critical, high, medium, low and info/informational. When KPI severity for a service reaches a defined level in tandem with changes in that service’s health score, it indicates a potential problem and triggers an alert.
When configuring thresholds and alerts, it’s best to maintain simple thresholding. Below are a few best practices:
In these cases, you can choose the “info” severity for all KPI results without impacting the service’s health score.
Adaptive thresholding is used to configure severity level thresholds in ITSI, which determine the current status of any given KPI. When a KPI’s value meets or exceeds its threshold conditions, the KPI status changes — from “high” to “critical,” for example — indicating a possible issue with a service. KPI thresholds are used with other configurations such as service health scores to drive more relevant alerts that help IT teams proactively troubleshoot and resolve performance problems.
Adaptive thresholding is important because it helps solve the challenge of monitoring cloud IT environments. Cloud service providers abstract away the hardware underlying their infrastructures, which makes it difficult for clients’ IT teams to identify the root cause of performance problems. Modern performance monitoring tools thus rely on machine learning techniques to collect, correlate, and interpret terabytes of data to gain insights into application performance, availability of services, latency and throughput, and other indicators of cloud environment health.
A central tenet of monitoring cloud environments is to continuously evaluate the health of the applications and services running on them to ensure optimal workflow. Adaptive thresholding is a critical tool in this regard as it enables organizations to understand the current status of their KPIs and proactively respond to status changes that may indicate a problem. This in turn helps them to prevent downtime that could result in dissatisfied customers and lost revenue.
Because infrastructure data can vary widely, ITSI supports three types of adaptive thresholding algorithms: standard deviation, quantile and range-based.
Adaptive thresholding helps IT teams continuously monitor the status of their KPIs to enable more meaningful alerts. It’s an important component of ITSI, which stresses the use of machine learning-driven analytics to monitor and troubleshoot cloud IT environments.
Machine learning is important in adaptive thresholding because of its ability to discover patterns, draw inferences and make predictions. Cloud IT environments produce terabytes of data every day, far more than humans can parse manually. Machine learning algorithms perform these tasks more efficiently and accurately making them an essential tool in all aspects of performance monitoring.
Adaptive thresholding commonly uses a couple of machine learning techniques to discover patterns in data and make predictions based on them: regression and classification.
Regression analysis examines a dependent variable (the action) and several independent variables (outcomes) and assesses the strength of the relationship among them. It’s commonly used to forecast trends, predict the impact of a particular action, or determine whether an action and outcomes are correlated. Regression analysis encompasses several commonly used algorithms including, simple linear regression, logistic regression and ridge regression.
Classification sorts data into categories for more accurate analysis. It uses different mathematical techniques, including decision trees and neural networks.
Cloud environments bring a host of business benefits to the enterprise, but their complexity can result in high noise levels, alert fatigue, and an inability to identify and respond quickly to performance issues. Adaptive thresholding is an essential technique for improving your service monitoring and empowering your IT team to head off issues before they degrade performance.
See an error or have a suggestion? Please let us know by emailing splunkblogs@cisco.com.
This posting does not necessarily represent Splunk's position, strategies or opinion.

The world’s leading organizations rely on Splunk, a Cisco company, to continuously strengthen digital resilience with our unified security and observability platform, powered by industry-leading AI.
Our customers trust Splunk’s award-winning security and observability solutions to secure and improve the reliability of their complex digital environments, at any scale.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2025 Splunk LLC All rights reserved.
