Saving Money with Apache Pulsar Tiered Storage

As companies start to look at rolling out real-time messaging systems, it’s important to look at the overall hardware costs. With some forward planning, companies can save as much as 85% on their overall storage costs.
Before we start getting into the cost comparisons, let me briefly show how Apache Kafka and Apache Pulsar store data, how they differ, and why these differences matter.
Data Storage in Kafka
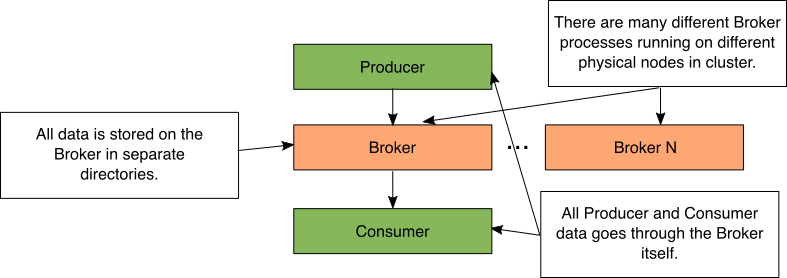
Figure 1: Simple Kafka storage diagram
In Kafka, the Broker process performs all data movement and storage. When the Producer sends data, it is sent to the Broker process. When the Consumer polls for data, it is retrieved from the Broker. As the Broker process receives data, it will store the data in separate local directories.
In a Kafka cluster, there are many different Broker processes running. Each of these Broker processes run on a physically separate computer or container.
Data Storage in Pulsar
There are several different ways a Pulsar cluster can be set up. This level of extensibility is how we can optimize our storage costs.
Simple Pulsar Setup

Figure 2: Simple Pulsar storage diagram
In Pulsar, the Broker process performs all data movement. When the Producer sends data, it is sent to the Broker process. When the Consumer has data pushed to, it comes from the Broker. As the Broker process receives data, it will store the data in a colocated BookKeeper Bookie. The BookKeeper Bookie is the name of the process in BookKeeper that stores the data.
In a Pulsar cluster, there are many different Broker processes running. Each of these Broker processes run on a physically separate computer or container.
Pulsar With Separate BookKeeper Cluster
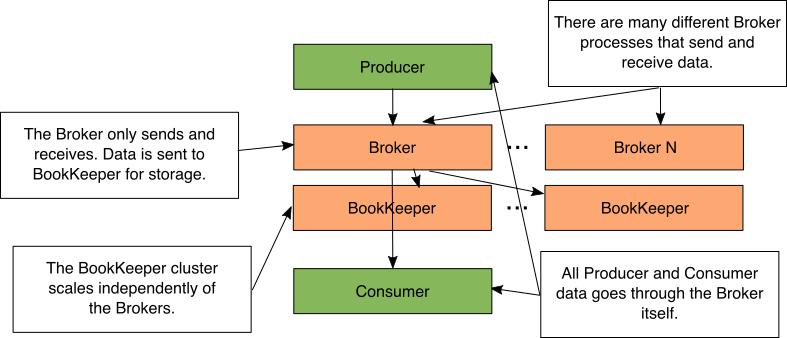
Figure 3: Pulsar with separate BookKeeper cluster
As you just saw, data isn’t stored directly by a Pulsar Broker. Instead, Pulsar Brokers use Apache BookKeeper to store their data. This decoupling of the send/receive and storage of the data allows you have BookKeeper running on another physically separate computer or container.
When the Broker goes to save a message, it will simply send the data to the BookKeeper process. This allows the BookKeeper cluster and Pulsar cluster to scale independently of each other. You could send/receive lots of messages that get stored for a short amount of time (many Pulsar brokers and few Bookies). You could receive few messages and store them for a long time (few Pulsar brokers and many Bookies).
A common question is if having the Broker and Bookie on separate machines causes performance issues. The Broker keeps an in-memory cache of recent messages. The reality is 99.9% of messages will be cache hits because most consumers are just receiving the latest messages.
Offloading to S3

Figure 4: Pulsar with separate BookKeeper cluster that is offloading to S3
Pulsar’s decoupled storage architecture really shines with a new feature in Pulsar called tiered storage. This allows BookKeeper to automatically move data from being stored on a Bookie to being stored in S3 based on policies configured by the administrator.
Note: while I’m calling out S3 as an option for the Bookie to offload into, it isn’t the only supported technology. There is support for Google Cloud Storage and upcoming support for Azure Blob Storage. You can think of S3 as shorthand for your supported cloud storage option of choice.
Despite the data being stored in S3, the Broker can still access data in S3 because the Bookie is responsible for data movement. The IO for S3 is slower than locally stored data.
The Key Differences For Storage
As you’ve seen, the major difference between Kafka and Pulsar for storage is the coupling. In Kafka, the storage is coupled to the Broker. In Pulsar, the storage is decoupled to BookKeeper.

Figure 5: Kafka Offload
As you might know, Kafka does have ability to put data into S3. This can be done manually by setting up Kafka Connect or writing a custom Consumer.

Figure 6: Kafka access
This offload to S3 does come with an important caveat as shown in Figure 6. Once data is offloaded to S3, it can’t be accessed via the Kafka API anymore. Now, all subsequent processing or consumption of the data has to be done with another compute engine that supports S3, or the data must be re-streamed back into a Kafka topic and processed.
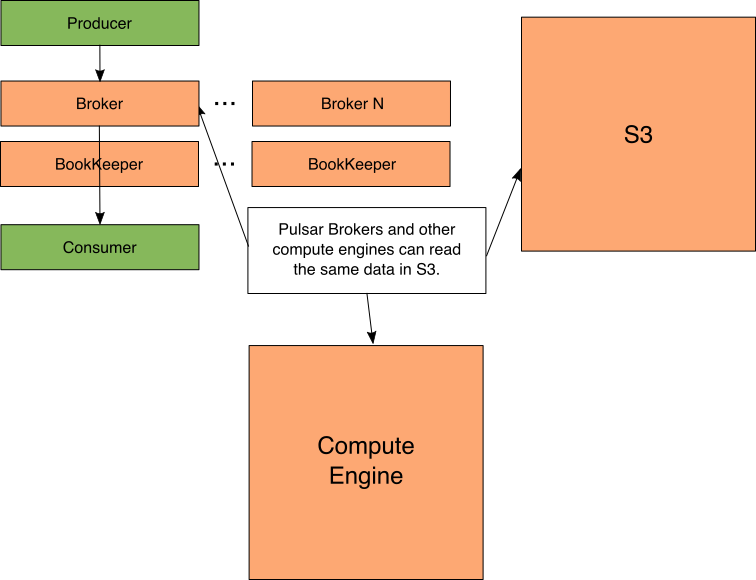
Figure 7: Pulsar access
With Pulsar, the data can be shared with a compute engine. This gives the best of both worlds because the Broker can still access old messages and the compute engine can too.
For example, Spark can process the old messages stored in S3 at the same time as a Pulsar Consumer could request them. Note that reading Pulsar’s data in other compute engines will need a custom input format that understands Pulsar’s on disk format. As of this writing, Pulsar supports connectors for Spark and Presto.
Calculating Costs
Now that we understand how Kafka stores data and the various ways Pulsar can store data, we can start to calculate our costs. To make this easier and more concrete, we’ll base our numbers on Amazon Web Service’s U.S. East (Ohio) Region January 2019 pricing. For S3 it costs $0.023 per GB month and for EBS Amazon EBS General Purpose SSD it costs $0.10 per GB-month of provisioned storage.
For this scenario, let’s imagine that we store 500 GB per day of messages. We need to store these messages for 14 days. That’s about 7,000 GB of raw event messages. In Kafka and Pulsar, data is saved 3 times for redundancy. That takes our storage requirements up to 21,000 GB. For Kafka and Pulsar (without S3), the storage alone would cost $25,200 per year.
With Pulsar and S3, we don’t need to store 14 days on BookKeeper. We can just store one day in Pulsar and the other 13 days in S3 (the majority of the time you’re consuming data that’s minutes old). That means we need 1,500 GB of EBS (500 GBx3 replicas) and 6,500 GB in S3 (remember that S3 doesn’t directly charge for redundancy). That would cost $1,794 per year for EBS and $1,800 per year for S3, for a total of $3,594. This obviously doesn’t include the S3 request costs, but those should be about $50-$300 per year.
That’s an 85.7% difference in price between the two, with no loss of data availability. This is obviously an example. To help you estimate the cost differences, I created a Pulsar_Storage_Savings spreadsheet. Just input your data and it will give you the price differences.
More On Costs
For Cloud users, the archival storage of data in S3 is already factored into the budget. This could make the savings even higher.
There are other, cheaper tiers of S3. These have lower SLAs, but even lower costs. You might be able to go even lower with these S3 tiers like Glacier. Prices for Glacier go all the way down to $0.004 compared to $0.023.
Given your use case and cluster needs, you may be able to optimize your costs further by choosing the right number of Pulsar Brokers versus BookKeeper Bookie nodes. Your EC2 costs are usually much higher than your storage costs.
By understanding the storage differences of Kafka and Pulsar, you can really optimize your storage spend. This gives you the flexibility to deliver what the business wants while still keeping your IT overhead down.
Thanks,
Jesse Anderson
Full disclosure: this post was supported by Streamlio. Streamlio provides a solution powered by Apache Pulsar and other open source technologies.


Related Articles
About Splunk
The world’s leading organizations rely on Splunk, a Cisco company, to continuously strengthen digital resilience with our unified security and observability platform, powered by industry-leading AI.
Our customers trust Splunk’s award-winning security and observability solutions to secure and improve the reliability of their complex digital environments, at any scale.

Subscribe to our blog
Get the latest articles from Splunk straight to your inbox.
