
Digital Resilience Pays Off
How resilient is your organization? Learn how to mature your digital resilience with this free guide.

In this blog post we will introduce the Apache Pulsar processors we have developed for the Apache NiFi framework and walk you through the development of a very simple NiFi flow that utilizes the new Pulsar processors.
Apache NiFi (short for NiagaraFiles) is a software project from the Apache Software Foundation designed to automate the flow of data between software systems. It is based on the "NiagaraFiles" software previously developed by the NSA and open-sourced as a part of its technology transfer program in 2014. According to the official Apache NiFi web site, it is "An easy to use, powerful, and reliable system to process and distribute data."
NiFi is one of the most popular open-source data collection frameworks available today, and it enables the collection and aggregation of data from multiple sources. It supports routing and transformation of data and publishing to multiple destinations.
NiFi provides several extension points that enable developers to add functionality to the NiFi framework to meet their needs. The processor interface is the basic building block used to comprise a NiFi dataflow, and also serves as one of the primary extension points for the framework. Apache NiFi currently has 100s of processors that allow you to process and distribute data across a variety of systems, but until now there was no native integration with the Apache Pulsar messaging system.
The Apache NiFi developers guide covers, in great detail, all of the steps required to develop a custom processor. I created the following NiFi processors which we will demonstrate in this blog:
I also created a controller service named StandardPulsarClientService that allows you to configure the Pulsar client connection properties including the broker URL, concurrency settings, and TLS security configuration once and re-use them across multiple instances of the processors. Details for obtaining and building the processors can be found in the Building the Apache NiFi Processors section at the end of this blog post.
In order to use the processors, we will first need to perform the following steps to create a environment with running instances of BOTH Apache Pulsar and Apache NiFi.
We will be using Docker to run the development environment, primarily because both Apache projects provide Docker images that make the process very easy.
Download and start the Apache Pulsar Docker image:
docker run -d -i --name pulsar -p 6650:6650 -p 8000:8080 apachepulsar/pulsar-standalone
Download and start the Streamlio NiFi Docker image, which is based on the Apache NiFi Docker image and has been modified to include our custom NiFi processors:
docker run -d -i --name nifi --link pulsar -p 8080:8080 streamlio/nifi
Open the Apache NiFi web interface by navigating to http:localhost:8080/nifi.
Now that we have a fully functional development environment, we can proceed to the next step, which is creating the Apache NiFi flow. From the NiFi UI, navigate to the processor icon in the upper left hand side of the toolbar and drag it onto the canvas.

Figure 1. Add a Processor to the Canvas
This will cause a pop-up dialog box to appear that lists all of the processors within NiFi and allows you to search for specific processors based on name or functionality. In order to navigate quickly to the Pulsar processors, go ahead and type "Pulsar" in the search box.
From the remaining list select the "ConsumePulsar" processor by double-clicking on the processor name in the list as shown below.

Figure 2. Select the ConsumePulsar Processor
Repeat the process of dragging the processor icon onto the canvas, and this time search for "Debug" and select the DebugFlow processor, positioning it below the "ConsumePulsar" processor that was already on the canvas.
Once the two processors are on the canvas, we need to connect them so that the data flows from the "ConsumePulsar" processor to the DebugFlow processor as shown below. In order to do this, simply hover over the "ConsumePulsar" processor until an arrow appears, then drag that arrow down onto the DebugFlow processor.
A dialog box will appear when you connect the two processors, for now just click on the "Add" button in the lower right-hand corner to accept the defaults. When you have completed these steps, your NiFi canvas should look like the figure below.

Figure 3. ConsumePulsar Data Flow
Now that we have the two processors wired together, we need to configure each of them before we can start the data flow.
We will start by right-clicking on the ConsumePulsar processor, and selecting the "Configure" option from the pop-up menu.

Figure 4. Configure ConsumePulsar Processor
This will bring up the "Configure Processor" dialog box, which we will use to edit the properties as shown below in Figure 5. To edit a specific property, you simply right-click on the "Value" column for the property you wish to change, type in the desired value and click "ok" to accept your changes. We will use this technique to update the following properties as follows:

Figure 5. Configured ConsumePulsar Processor
Next, we will need to create a Pulsar Client Service, that will handle all the details of connecting to Apache Pulsar. From inside the Configure Processor dialog box, right-click on the "Pulsar Client Service" property. This time, instead of a pop-up text box you will be presented with a drop-down box as shown in Figure 6. Select the option to "Create new service".
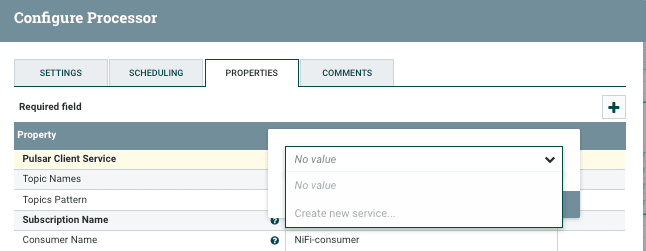
Figure 6. Adding a Pulsar Client Service Property
An "Add Controller Service" dialog box will appear with only one valid option in its dropdown list of compatible controller services, so go ahead and click on "Create" to accept that option.

Figure 7. Adding a Controller Service
After you click on the "Create" button and have created the Controller Service, you will be taken back to the "Configure Processor" dialog box. However, YOU ARE NOT DONE, as the Controller Service itself needs to be configured to point to the Pulsar Broker URL.
Until you complete this step, you won't be able to connect to Pulsar. Fortunately, you can simply click on the arrow icon to the right of the "StandardPulsarClientService" value to configure the Controller Service. (If a pop-up box appears asking you if you want to save your changes, select "yes" to proceed.)

Figure 8. Navigate to the Controller Service List
You should see a screen similar to Figure 9 that lists all of the configuration properties available for the Pulsar Client controller service. Fortunately, there is only one required property, the Pulsar service URL, which enables us to connect to the Pulsar cluster we wish to interact with. If you recall from earlier, when we launched the Docker container for NiFi, we specified a --link switch, which creates an entry in the /etc/hosts file named "pulsar" that has the Docker internal IP address associated with it. We did that in order to simplify the configuration, by allowing us to use the "pulsar" host name, rather than a Docker assigned IP.

Figure 9. Configure the Pulsar Broker URL
After you update the Pulsar Service URL property and click on "Apply", you will be taken back to the controller service listing, only this time you should see a small lightning bolt icon next to the gear icon you used to configure the controller service. The controller service state should also have changed to "Disabled". This indicates that while the controller service is properly configured, it is not running.
Next, we need to click on the lightning bolt icon in order to start the controller service. In the dialog box that appears, select the second option in the scope drop-down list and click on "enable". Doing so will not only start the controller service, but also any processors that use the controller service, such as the ConsumePulsar processor in our data flow.

Figure 10. Enable the StandardPulsarClientService Controller Service
Lastly, we need to auto-terminate the "success" and "failure" relationships of the DebugFlow processor by right-clicking on the processor, selecting configure from the menu, and checking both of the checkboxes on the settings tab. Once the configuration looks like Figure 11 below, click on "Apply" to accept the changes.

Figure 11. Auto-terminate both relationships in the DebugFlow processor
Right-click on the DebugFlow processor and select "Start". Thus far, we have started a Pulsar consumer within NiFi which will create the topic and the subscription within Pulsar itself. However, we should not see any data at this time, as the topic will be empty. Next, we will need to create a similar flow for publishing data into the Pulsar topic.
From the NiFi UI, navigate to the processor icon in the upper left hand side of the toolbar and drag it onto the canvas. Go ahead and type "Pulsar" in the search box like you did in the previous section, this time select the "PublishPulsar" processor from the remaining list.
Repeat these steps and select the "GenerateFlowFile" processor, and place it directly above the "PublishPulsar" processor on the canvas and connect these processors as shown below.

Figure 12. Adding the Publish Pulsar Data Flow
The GenerateFlowFile processor is a special processor used for testing within the Apache NiFi framework. It generates random data at periodic intervals, which makes it useful as a data simulator. In our particular use case, we are going to use it to generate a large amount of data that will be published to Apache Pulsar. In order to do this, we need to configure the processor properties as shown in figure 13.

Figure 13. Setting the GenerateFlowFile Processor Properties
Then we can control the amount of data generated by adjusting the run frequency in the scheduling tab of the processor properties dialog. For now we will schedule the processor to generate the data at a rate of 1 message per second by double-clicking on the "Run Schedule" property and entering 1 sec as shown below.

Figure 14. Scheduling the GenerateFlowFile Processor
We will also configure the PublishPulsar processor to use the same controller service we created earlier, and have it publish data to the same Pulsar topic name. We will leave the other configuration settings at their default values for now.

Figure 15. Setting the GenerateFlowFile Processor Properties
We start all processors on the canvas by selecting each of the processors, right-clicking and selecting start from the drop-down menu.
We can see that the randomly generated data is flowing from the PublishPulsar processor thru Pulsar to the ConsumePulsar processor at the same rate. When the data flow is running, the GenerateFlowFile processor is producing a random string of 100 bytes every second, and sending it to the PublishPulsar processor, which in turn publishes it to the configured topic in Pulsar, which in this case is persistent://sample/standalone/ns1/nifi-topic. The PublishPulsar processor also increments its "In" counter to reflect that fact that it has received another message.
Once the message is published to the persistent://sample/standalone/ns1/nifi-topic topic on Pulsar, the ConsumePulsar processor consumes the message, routes the message contents to the DebugFlow processor, and increments its "Out" counter to reflect the fact that it has produced another message from the source system. Given that the PublishPulsar processor's "In" counter matches the value of the ConsumePulsar processor's "Out" counter, we can easily see that all of the messages have been consumed.

Figure 16. Synchronous Mode operation
In the previous configuration, we were publishing and consuming the messages in synchronous mode. However, the NiFi processors are both capable of exposing the asynchronous messaging capabilities of the Apache Pulsar framework, which allows us to achieve a much higher level of throughput.
Let's stop the current running flow by selecting all of the processors and clicking on the "stop button" inside the control pane as shown:

Figure 17. Stop all Processors
Next, we will make the necessary changes to enable asynchronous publishing and consumption of messages. First, we will enable asynchronous message publishing by changing the following properties in the PublishPulsar processor:

Figure 18. Configure PublishPulsar Processor for Async
Next we will make similar changes to the ConsumePulsar processor to enable asynchronous message consumption.

Figure 19. Configure ConsumePulsar Processor for Async
Lastly, we will make some changes to the GenerateFlowFile process to increase the volume of data generated, as the asynchronous operation will be able to handle a much larger volume of data. We can easily accomplish this by adjusting the run schedule to 0 seconds, which instructs the processor to generate the data as fast as possible.

Figure 20. Configure GenerateFlowFile Processor for Async
Once these changes have been made and saved, we can restart the all of the processors again and observe the increased number of messages produced and consumed by the processors.

Figure 21. Restart the NiFi Processors in Async mode
After we let the processors run for a few minutes, we can see the increase in throughput of the messages.

Figure 22. NiFi Processors Running in Async mode
All of this code has been published in the Streamlio repository, and is covered under the ASF 2.0 license. If you want to build the code yourself by hand, here are the steps to follow:
Clone the nifi-pulsar-bundle repo
user@host:$ git clone git@github.com:streamlio/nifi-pulsar-bundle.git
Change into the clone directory
user@host:$ cd nifi-pulsar-bundle
Build the artifacts using Apache Maven
user@host:$ mvn clean install
Verify that BOTH nar files were created.
user@host:$ ls -l nifi-pulsar-nar/target/nifi-pulsar-nar* user@host:$ ls -l nifi-pulsar-client-service-nar/target/nifi-pulsar-client-service-nar*
You can now copy BOTH of these NAR files to your ${NIFI-HOME}/lib folder and restart NiFi to start using these processors in your environment.
This article introduced you to the Apache NiFi framework and the new Apache Pulsar processors. We walked through the development of a very simple data flow that utilizes the new Pulsar processors and showed how to modify some of the properties of the processors to support asynchronous message publishing and consumption.
In subsequent blog posts, we'll delve more deeply into some of the more advanced features of the Pulsar processors, including record-based processing.
----------------------------------------------------
Thanks!
David Kjerrumgaard

The world’s leading organizations rely on Splunk, a Cisco company, to continuously strengthen digital resilience with our unified security and observability platform, powered by industry-leading AI.
Our customers trust Splunk’s award-winning security and observability solutions to secure and improve the reliability of their complex digital environments, at any scale.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2025 Splunk LLC All rights reserved.
