
Digital Resilience Pays Off
How resilient is your organization? Learn how to mature your digital resilience with this free guide.

Today’s software is incredibly complicated and creates tons of data. Metrics, logs, and traces are generated constantly by hundreds of services for even simple applications. Every transaction can generate on the order of kilobytes of metadata about the transaction — and multiplying that to account for even a small amount of concurrency can create a few megabytes a second (or ~300GB/day) of data that needs to be captured and analyzed for later use. The scale only grows as your application gets more users and more services. The questions you can answer about your business are legion and you need data to it. How long do my customers spend on my site? What happens to user experience if one of my services is performing slowly? How do I know if there are problems at all? All of this is powered by Observability, which is powered by data.
One solution to deal with this data is to send it all to your Observability system. Obviously, that’s the easiest way, and it makes sure you don’t miss anything. The challenges with doing this are twofold:
Most Observability tools charge you based on the volume of data you send them. The more data you send, the more you pay. What’s worse, many vendors make you guess how much you’ll send in advance, and punish you financially for being unable to adequately see the future. Additionally, many systems simply can’t handle large volumes of data. They’re not built to ingest everything, taking a ‘most of the data is good enough’ approach. When your organization grows and your data streams approach hundreds of MB, GBs, or even TBs worth of data per second, your Observability platform has to be able to keep up.
 To work around these issues, many providers suggest that you ‘sample’ (or throw away some of) your data. Many of them spin this as a way to save you money — by sending less data, they charge you less to analyze and store it. However, throwing away data has serious consequences. In many cases, Observability providers pushing sampling are doing so without regard to those consequences, and they’re doing so because their systems actually can’t handle the volume of data generated by real-world systems.
To work around these issues, many providers suggest that you ‘sample’ (or throw away some of) your data. Many of them spin this as a way to save you money — by sending less data, they charge you less to analyze and store it. However, throwing away data has serious consequences. In many cases, Observability providers pushing sampling are doing so without regard to those consequences, and they’re doing so because their systems actually can’t handle the volume of data generated by real-world systems.
Sampling data can easily make you miss critical issues. If you have a system that performs normally most of the time but has a few bursty moments where latency spikes above 5 seconds, for example, your sampling methodology may not catch that in a timely fashion, or even at all. Imagine for a moment that these latency spikes only occur with big orders. Imagine that these latency spikes cause people to abandon these orders. Every single abandoned order is money left on the table. If your app is unreliable, or slow, people will hop on social media to complain, costing you even more due to a loss of goodwill.
Fundamentally, sampling is at odds with Observability.
There are various workarounds to the missing data issue that providers who suggest sampling will tell you about, but fundamentally sampling is at odds with Observability — you simply don’t have full insight into a system if you’re deliberately ignoring parts of its output.
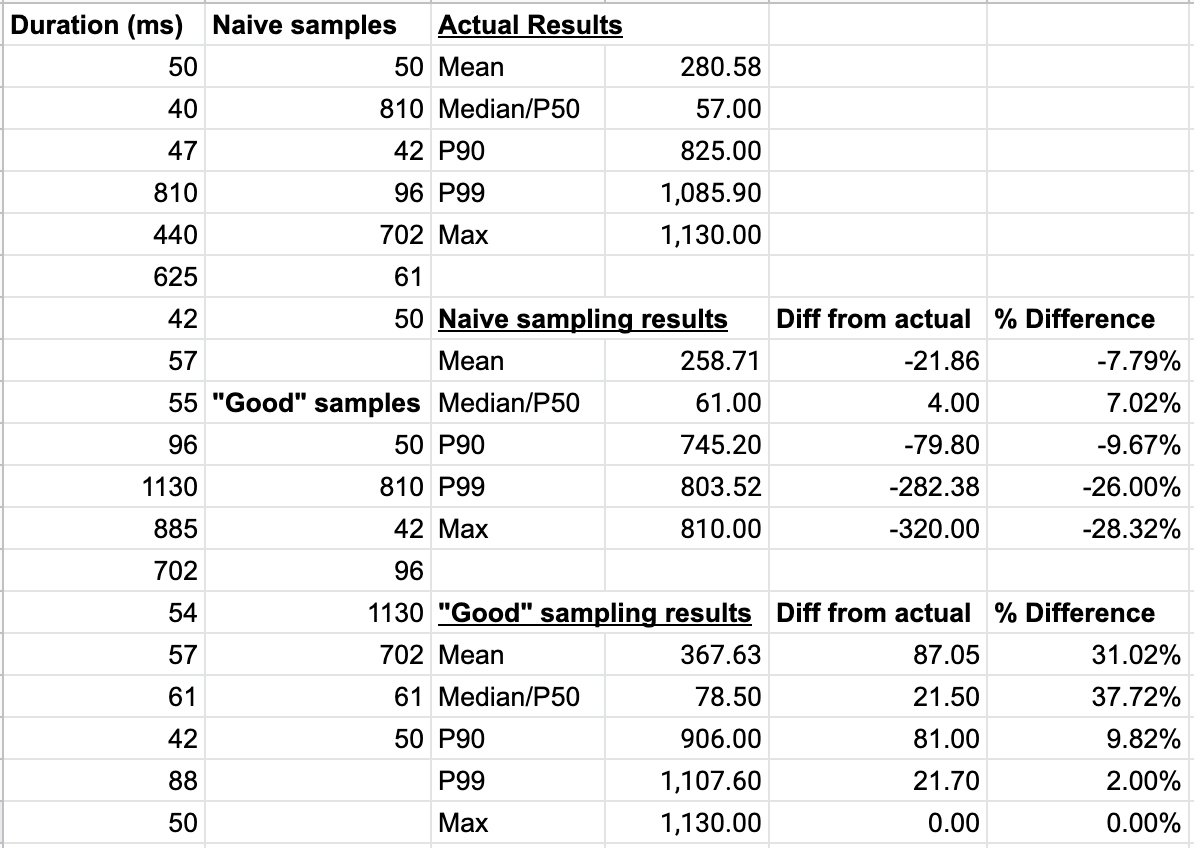
Let’s illustrate this with an example. Many Observability tool providers who sell sampling-based systems will say that using sampled data points give you the same insight as averages of every piece of data, but this is simply false. In our example below, we show you the duration metrics for calls into an order processing service. This order processing service, like many other services, sometimes has some trouble keeping up with demand and has bursty duration metrics.
You can see all the data in the leftmost column. You can also see it is as analyzed by a naive sampling system that takes every 3rd piece of data (note that most vendors who sample sample far less than 33% of events) and then analyzed with an ‘industry leading’ sampling system that does naive sampling described before and also captures any transaction that took over 1000ms:
As you can see, the sampling based systems simply don’t provide you with an accurate picture of what’s happening. Both of these systems do not (and can not) show you the real state of your system. Depending on what metric you choose, sampling systems can under or overestimate duration by almost 38%! Many legacy systems were built for averages, but with modern use of SLOs and error budgets, averages aren’t as useful anyway. Percentiles give you more accurate representations of the state of your services — and the sampling systems get them quite wrong in our example above.
Finally, let’s briefly discuss the effort involved in instrumenting your applications for Observability. If you aren’t using an OpenTelemetry-native system, you likely had to install a heavyweight agent and manually instrument all of your applications to ship off metrics, traces, and logs. Even with an OpenTelemetry system, there was still development effort required to configure and set up the instrumentation and to verify that all the appropriate data was arriving to your Observability platform.
Sampling is taking that effort and completely wasting it. By using an Observability tool that samples, you’re diminishing the value of your Observability platform, and you’re also not getting the full return on your investment in instrumenting applications in the first place. Why would you spend time and money creating systems that can emit all this data, only to dump half of it on the ground? It just doesn’t make sense, and it certainly doesn’t save money. In fact, it does the exact opposite by making you miss out on critical insights at the most relevant time.
![]() If you need a system that doesn’t throw data away and that was built for scale, you need Splunk Observability Cloud. Start your free trial of Splunk Observability Cloud
If you need a system that doesn’t throw data away and that was built for scale, you need Splunk Observability Cloud. Start your free trial of Splunk Observability Cloud
today.
To learn more about Observability in general, review the "Beginner’s Guide to Observability."

The world’s leading organizations rely on Splunk, a Cisco company, to continuously strengthen digital resilience with our unified security and observability platform, powered by industry-leading AI.
Our customers trust Splunk’s award-winning security and observability solutions to secure and improve the reliability of their complex digital environments, at any scale.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2025 Splunk LLC All rights reserved.
