





Digital Resilience Pays Off
How resilient is your organization? Learn how to mature your digital resilience with this free guide.

Howdy, partners. I see you've galloped over here on that dashing Buttercup pony, but you've got to hold your horses! Buttercup can't be scarfing down all of those carrots and sugar cubes and then gallop at full speed. We need to make sure that Buttercup paces herself.
When using Splunk, there are a few things that can be done to optimize searches in order to speed them up as well as decrease the amount of memory used.
 Search Mode
Search ModeSearch Mode tells Buttercup to either trot, canter, or gallop. Giddyup!
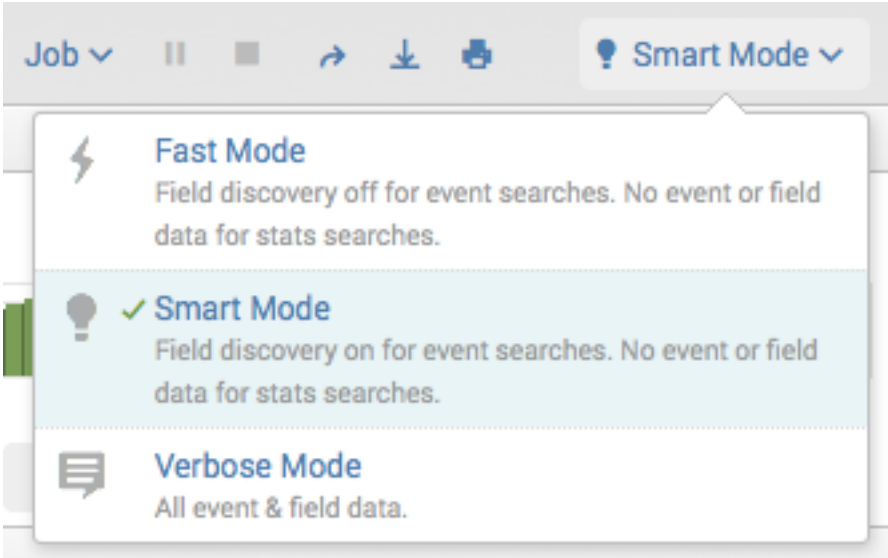
Underneath the search bar, there is an option to change the search mode. Options are Verbose, Smart, and Fast.
Verbose Mode returns as much information as possible from the data, including all events and field information. It uses the most system resources out of all of the search modes. It is a great mode for short time frames and digging into data.
Smart Mode is best when exploring data, as it will only pull back raw events if there are no transforming commands in the search, and will display any field extractions in the events. If there are transforming commands like stats, chart, or timechart in the search, it will only return the aggregated/transformed events. This saves on system resources and results in faster searches.
Fast Mode is my personal recommendation, as it uses the least amount of system resources. It is great to use Fast Mode when merely checking if data is present or not (in combination with | tstats) or after a search is already built.
Scheduled searches and dashboards will automatically execute in fast mode.
We can't expect Buttercup to gallop into infinity, that poor girl is going to need a break!
When exploring the data and/or prototyping new searches, it is recommended to keep the time range short (e.g. last 60 minutes). The time range should be made as short as feasible.
As all time searches consume a lot of resources by scanning unnecessary data, you should instead constrain your search window as much as possible. Remember, sharing is caring, and we should all share Splunk resources, since, likely, it is a shared environment amongst many users.
Imagine, if you will, a saddlebag on little Buttercup, full of unnecessary items from your last trip to the Splunk Swag Store. She sure would go a lot faster and a lot further if towards the beginning of the trip some of those items were offloaded and only the necessary items were in the bag.
A few things to remember about filters: time is the most efficient filter (smaller windows = faster results) and inclusion is better than exclusion (field=foo is better than field!=bar or NOT field=bar).
Filtering using default fields is very important. Adding index, source, sourcetype, etc. filters can greatly speed up the search.
The sooner filters and required fields are added to a search, the faster the search will run. It is always best to filter in the foundation of the search if possible, so Splunk isn't grabbing all of the events and filtering them out later on. As mentioned above, using transforming commands right away also is amazing at reducing your data.
Example:
index=foo
|stats count by host
|search host="bar"
index=foo host="bar"
|stats count by host
By adding the filter host="bar" to the foundation of the search, Splunk will only search for events where the host field has a value of "bar". It should be noted that in newer versions of Splunk (6.6+), the optimizedSearch (found in the job inspector) runs this optimization for you, however, it is good practice to filter as much as possible in the preliminary search.
Also, if adding a filter without the field, it will find events with the keyword bar, surrounded by breakers, such as commas, spaces, or dashes. For example, index=foo bar would search any data with the term bar in it, including -bar, bar”, or _bar, however it will not find terms such as barley.
If you know your data has a lot of fields, but not all of those fields are needed and aren't in the search criteria, you can use the fields command to limit what is being brought back, which will also speed up the search.
Example:
index=bar
|fields host cpu
The above example queries all data in index=bar but only brings back the data from the fields command (even if there are null values) which limits how much gets brought back for doing more efficient commands later on.
When all the world is holding out sugar cubes, hay, carrots, and grass galore, it is a good thing Buttercup has the option to sample it all!
Another way you can grab a subset of events is to use the head command. This is not a random subset, but instead grabs the N most recent events. This can be useful if you are just wanting to see the events before or while creating a search or to make sure events exist.
Now, I'm sorry that Buttercup doesn't have some fancy computer like those newfangled electric vehicles, so she can't just tell you where she's been or how fast she went. I will tell you that if you know how far you and that pony went and how long it took, that's a good benchmark for improvements.
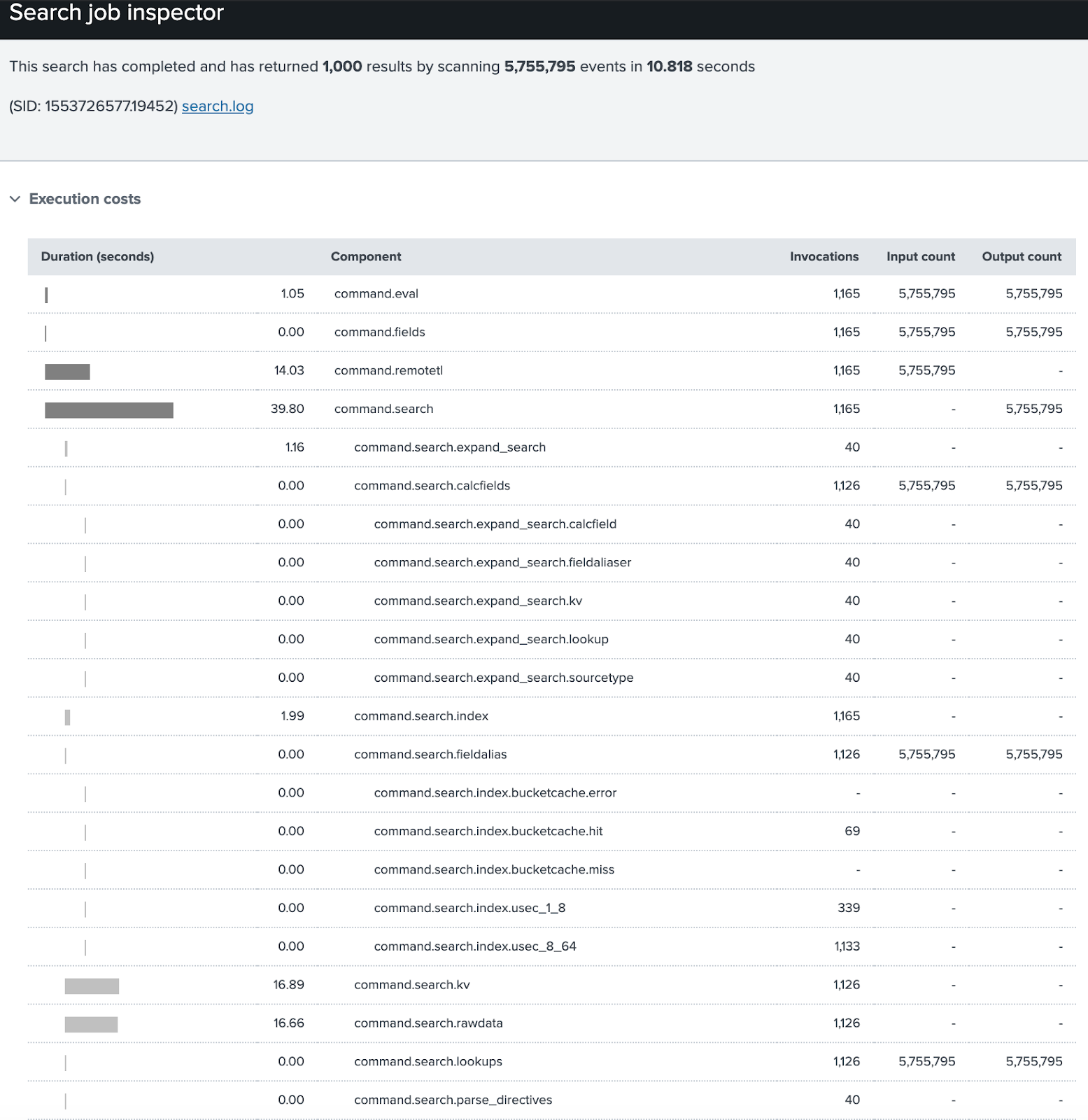
Using the job inspector can be tricky. It's full of a lot of information, however it is extremely useful in troubleshooting and benchmarking, as well as optimizing searches.
By clicking on Inspect Job, a new window will pop up with all sorts of information on the search that was just ran.
In terms of optimizing searches, the key components to look at would be:
Using these components, it is the best way to see what commands are taking the most time and could perhaps be adjusted in the search. That could be compared to the results/second and events/second benchmark to see if any changes made have made the search more efficient.
When trying to benchmark search optimization, run the original search and optimized search a few times and check both the time it took to run as well as the scanCount. The lower the scanCount, the more optimized the search is on the indexers and will likely run faster. You can also check the command components and the search duration to check if the search is optimized for the search head.
Buttercup is in the stable, munching on some tasty grass. Once Buttercup leaves that stable to taste that greener grass on the other side, there's no turning back!
Distributable streaming commands are commands that can be run on the indexer or the search head. Some of these commands include eval, rex, where, fields, spath. Here is a complete list of distributable streaming commands, for reference.
If these commands are run before any other command types, they are run on the indexers - that's a good thing! If any distributable streaming commands are run after other command types, they are run on the search head.
We all know that Buttercup has many different beautiful faces, and well, that's all I've got to say about that.
Transforming commands include table, chart, timechart, stats, top, rare, contingency. These commands take the data and transform it into a format that can be visualized in various charts. See this Splunk doc for a complete list of transforming commands.
Many searches use transforming commands and it is important to understand the best way and place to implement them.
The use of these commands will make fields not identified within these commands unusable. The following code only defines the component and host fields. Any other fields will not be able to be used after this stats command unless created using eval statements or brought in with data enrichment operators.
|stats values(component) as component by host
As mentioned previously, filter results if possible before the transforming command, and only aggregate the needed fields.
Various ways to neigh at your Buttercup.
Generally speaking, stats (with latest/earliest) and dedup are commonly misunderstood and therefore mistakenly interchanged, and stats or eventstats can commonly be used in place of transaction. It is important to know when all of these commands are needed, because they all serve a purpose.
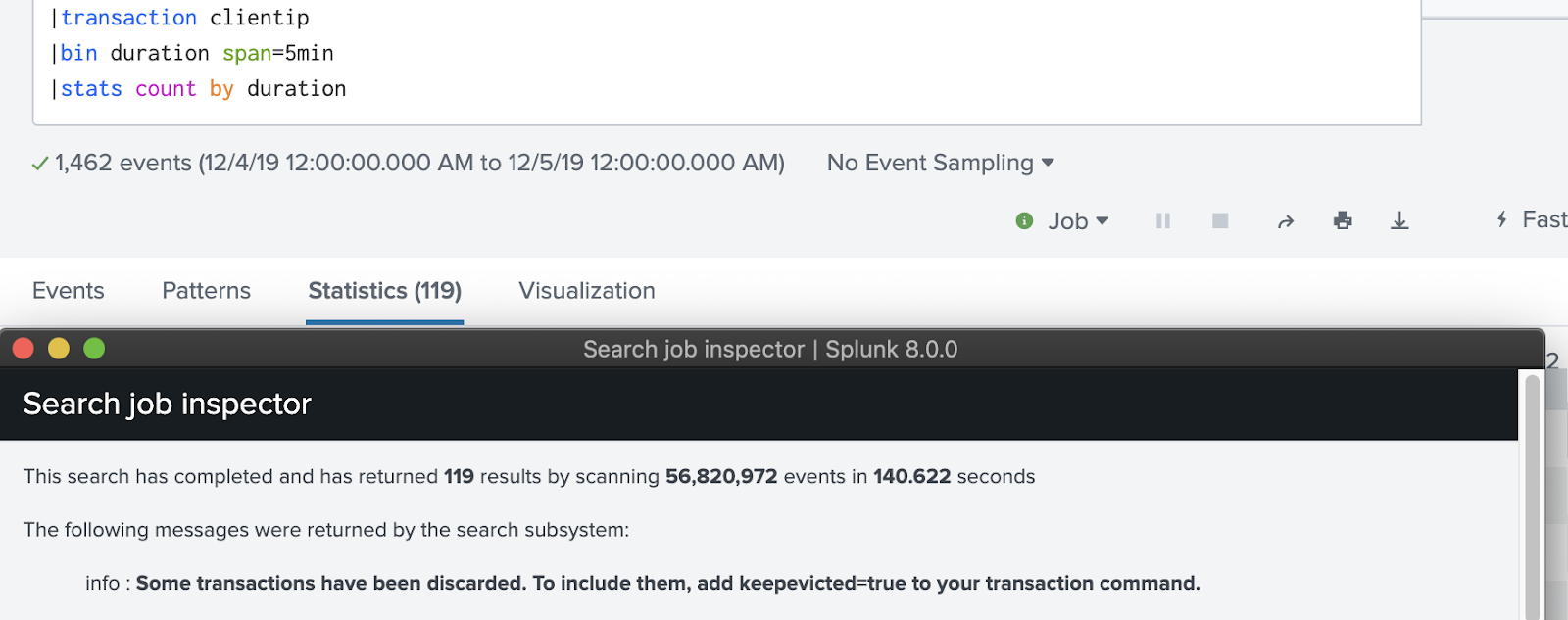
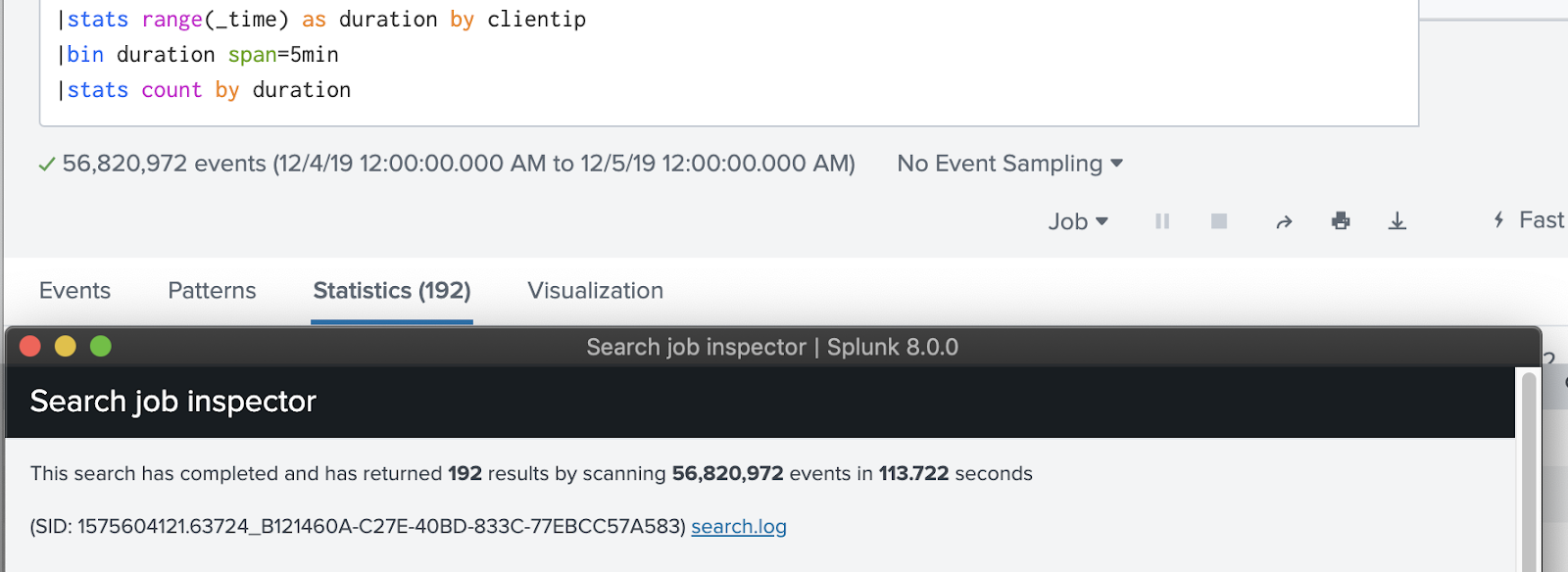
First, stats and transaction:
|transaction clientip |bin duration span=5min |stats count by duration
|stats range(_time) as duration by clientip |bin duration span=5min |stats count by duration
The time to use transaction, however, is when the events in question start with or end with a specific pattern (ie: | transaction clientip startswith="login"), or when the transaction IDs are reused after some time (ie: | transaction clientip maxpause=3600).
There are differences between using a stats command to remove duplicates and dedup.
Imagine you have a field id that needed to have duplicates removed, and another field message has null values.
| gentimes start=-3 | eval _time = starttime | fields _time | sort - _time | streamstats count | eval id = if(count%2=0, "even", "odd"), message = case(count>1, "error")
This first table is when you apply stats to the search. It will grab the latest NOT NULL value that matches the id. If my stats command used earliest, it would grab the earliest value, etc. It will skip any null values.
| stats latest(message) by id
This table is when you apply dedup to the search. It will grab the entire latest event for the matching id.
| dedup id | table id message
Please be cautious when choosing which command you are using, because the results can differ, depending on event coverage of each field. The use of one command over the other depends on the use case, as both of the above searches are producing accurate results.
The where command is for comparing two fields or filtering with eval functions (ie: | where field1>field2; | where _time<=relative_time(now(),”@w”)) and the search command is for filtering on individual fields (ie: | search field>0 field2>0).
eventstats will write aggregated data across all events, still bringing forward all fields, unlike the stats command. It is better to run this command AFTER running a transforming command, because it needs all the data before it can start processing.
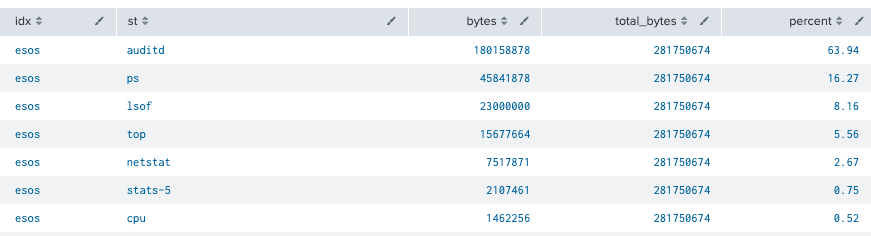
This example shows us that a new column is created called total_bytes with the eventstats command and sums all data from the bytes field grouped by the idx field. This helps us evaluate the percentage of bytes each sourcetype (st) is indexing in each index during our timerange.
index=_internal sourcetype=splunkd component=LicenseUsage type=Usage|stats sum(b) as bytes by idx st|eventstats sum(bytes) as total_bytes by idx|eval percent=round((bytes/total_bytes)*100,2)|sort idx - percent
streamstats will aggregate data in more of a rolling fashion. It is better to run this AFTER a transforming command, because this command runs on the search head!
Streamstats can be very useful for many different reasons. I suggest reading the documentation for the optional arguments that it offers. This example shows a very basic use for it, which is to basically add a row count by the idx field. This way, I can then search for the top 3 indexes, or if I had sorted the other direction, I could search for the bottom indexes.
index=_internal component=LicenseUsage|stats sum(b) as bytes by idx st|sort idx - bytes|streamstats count by idx|search count<=3
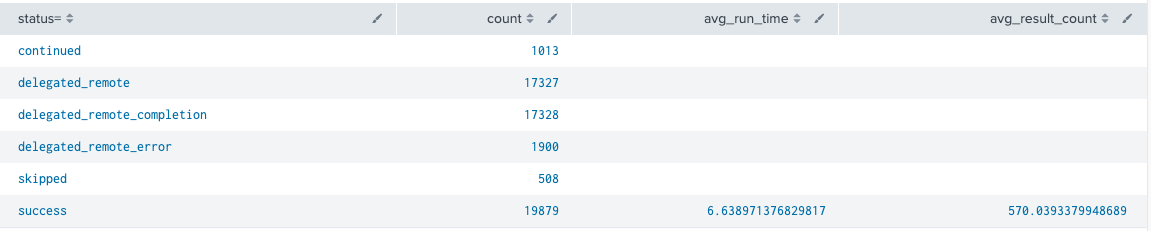
tstats is a very useful and efficient command. It can only be used with indexed fields, however, in v8.0.0+ there is a way to utilize a PREFIX option to help search data when the fields might not be extracted at index-time.
|tstats count avg(PREFIX(run_time=)) as avg_run_time avg(PREFIX(result_count=)) as avg_result_count where index=_internal sourcetype=scheduler by PREFIX(status=)
One thing to understand with the PREFIX option, though, is that it will not work with major breakers, such as double quotes. So if the field in your raw events is st=”ps”, the PREFIX option will nullify everything after that first major breaker.
Macros are incredibly helpful. Macros are saved SPL that can be inserted into searches. These can come in handy when a search is used in multiple locations, because if it ever needs to be updated, it only needs to be updated in the macro, not in every knowledge object it might be in! Splunk software includes a macro called comment that allows users to add inline comments in the SPL.
`comment("create a timechart for each component")`
|timechart count by component
Macros are also very helpful for data models or dashboards when defining indexes or sourcetypes (or really any type of data) that might need to change. This way the edit only needs to happen in the macro instead of in multiple places.
table and fields are commands often used interchangeably. They both select fields defined in the command, however table displays the results in a tabular format, whereas fields simply keeps or removes fields from results.
When to use fields:
When to use table:
fillnull is a useful command in that it can fill the empty field values with a string of your choosing. The important thing to remember when using fillnull is that when you don’t specify a field or field-list, it will look for empty values in all fields and bring all data back to the search head. When this command is used, it is best to specify the fields needing to be filled, unless it is being used after a transforming command, like timechart, since all of the results are already on the search head.
With all of this amazing grooming, Buttercup is sure to be best in show!
There are definitely many more things to know about how to use Splunk efficiently. Make sure to check out the additional resources below, and to ask questions on Splunk Answers and don’t be shy on our Community Slack channels! If you aren’t already in Community Slack, you can sign up for it using this form.
I’d also love to take a quick moment to thank the amazing people in the SplunkTrust who helped me on this blog (and the first one!). It takes a village to harvest knowledge, and I’d just like to give the whole lot of them a big thanks for reviewing and giving feedback!
December 2019, Splunk Enterprise v8.0.0

The world’s leading organizations rely on Splunk, a Cisco company, to continuously strengthen digital resilience with our unified security and observability platform, powered by industry-leading AI.
Our customers trust Splunk’s award-winning security and observability solutions to secure and improve the reliability of their complex digital environments, at any scale.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2025 Splunk LLC All rights reserved.
