
Digital Resilience Pays Off
How resilient is your organization? Learn how to mature your digital resilience with this free guide.

Driven by digital market shifts, organizations are adopting cloud and cloud-native technologies to deliver a better end-user experience, scale efficiently — both up and down —and increase innovation velocity. While distributed cloud architecture brings agility, it also brings operational complexity. Therefore, developing effective observability practices is all the more important for delivering a flawless end-user experience for cloud applications.
Typically, SRE teams set up monitoring dashboards and alerts. These teams are, however, separate from app development teams and have limited knowledge of application-specific logic and metrics, resulting in silos. Many times, on-call teams don’t know about the root causes of performance anomalies before the end-user experience is impacted.
Advanced DevOps teams following the “you build it, you run it” approach grapple with idiosyncrasies of traditional monitoring tools, each of which has its distinctive approach for creating observability assets removed from code. Observability is also often treated as an afterthought – it only gets deployed in production environments. This approach, which works best when systems fail in predictable ways, no longer works in distributed cloud environments. Distributed systems can fail in unpredictable ways and observability tooling needs to identify and provide insights on performance anomalies caused by “unknown unknowns." By instrumenting everything, developing observability assets alongside application development and using effective observability tooling DevOps teams get actionable insights along the entire software release cycle.
Just as Infrastructure as Code applies software engineering practices to configuration and management of infrastructure, Observability as Code enables DevOps teams with consistent practices to observe the state and behavior of a system in different environments.
The idea behind Observability as Code is that you develop, deploy, test and share observability assets such as detectors, alerts, dashboards, etc. as code. Doing so gives you the following benefits:
Automated, repeatable assets: Once developed, assets such as dashboards can be easily deployed and re-created as needed in different environments, thus eliminating the toil and the need to manually recreate such assets
Shareable best practices: Development teams can leverage their domain-specific knowledge to identify the most appropriate metrics to monitor the performance of their applications
Effective DevOps collaboration: By leveraging Git repositories, observability assets such as alerts can be created and fine-tuned by anyone in the organization with a simple pull request
HashiCorp Terraform is a widely used product to provision infrastructure, for any application, using an array of providers for any target cloud platform. Enterprises can either run it in the cloud with Terraform Cloud, manage it on their own with Terraform Enterprise. Since monitoring — dashboards, alerts and more — is a part of your infrastructure, it’s helpful to manage it in a similar way. Most users will use version control systems like Git to store the configuration files. With code stored in Git, users can borrow best practices from software engineering to version, collaborate and iterate on code. With Observability as Code, enterprises get automation, visibility and shareable assets that can be used across the organization to create consistent workflows for provisioning observability.

SignalFx is available as a Terraform Provider to define and configure SignalFx resources via HashiCorp Configuration Language (HCL).
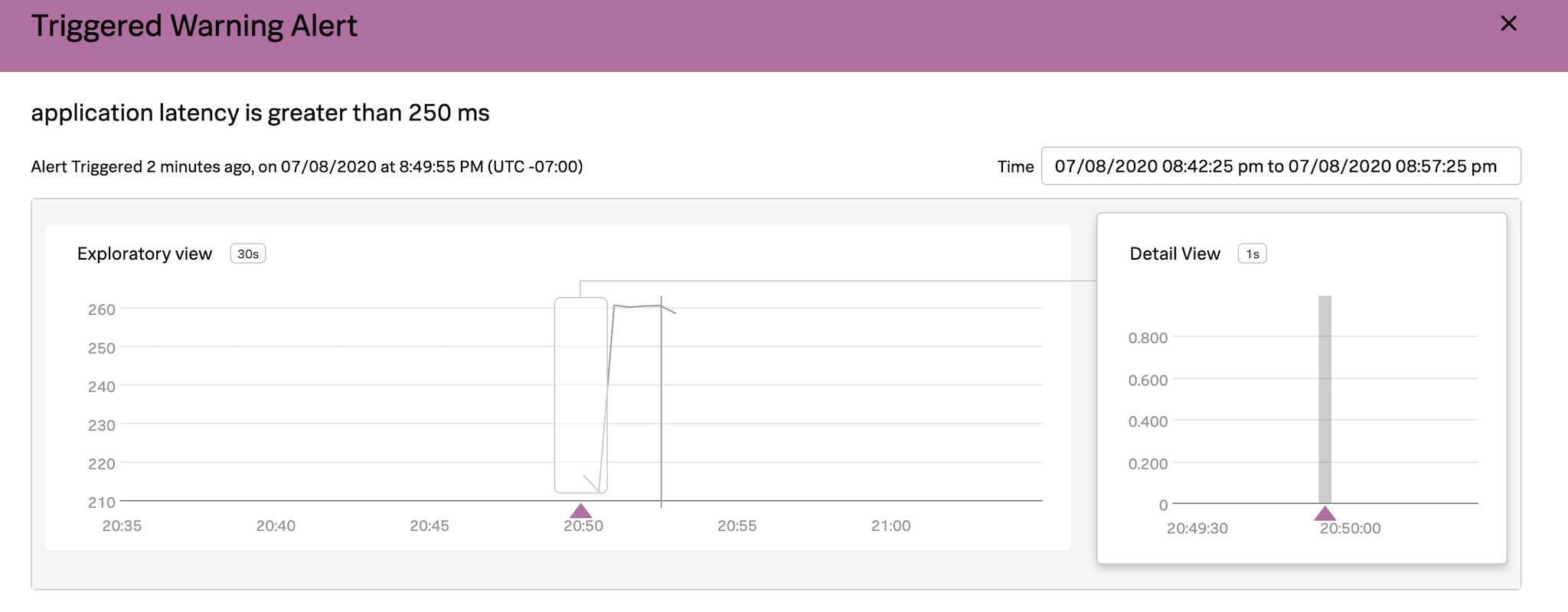
Getting started with provisioning observability assets is straightforward. Let’s create a simple alert that will fire when the max latency of an application transaction exceeds 250 milliseconds for a minute. Let’s start by creating a configuration file: main.tf.
provider "signalfx" {# It is strongly recommended to use secret management Terraform Provider such as Vault
auth_token="<<your access token>>"
api_url = "https://api.us1.signalfx.com" #use your custom SignalFx URL
}
resource "signalfx_detector" "application_latency" {name = "application latency is high"
description = "SLI metric for application latency is higher than expected."
program_text = <<-EOF
signal = data('demo.trans.latency').max() detect(when(signal > 250, '1m')).publish('application latency is greater than 250 ms')EOF
rule {description = "Application latency was high for last one minute"
severity = "Warning"
detect_label = "application latency is greater than 250 ms"
notifications = ["Email,amitsharma@splunk.com"] #you can also configure slack, VictorOps and others
}
}
You can now run `terraform init` to set up Terraform’s infrastructure and install the SignalFx plugin. Next, run `terraform plan` to check and validate all the actions Terraform is going to take when creating this alert. Then, `terraform apply --auto-approve` will execute the steps and create the detector.
Next, let’s create a dashboard to monitor critical metrics such as latency over time, the total number of transactions processed, etc. Terraform Cloud provides remote Terraform CLI execution, version control integration and Terraform state management. You can also enforce policies on monitoring resources using Sentinel such as alert notification to specific teams for specific environments.

In this case, we created a dashboard with multiple charts. Terraform Cloud is integrated with GitHub repository and can automatically trigger Terraform runs when changes are committed to a specific branch. You can also queue Terraform plans manually as we did in the example above.
Point-and-click UI makes it easy for anyone to create charts, detectors intuitively, without the need to learn a new language. Many solutions in the market take an either-or approach. With SignalFx you don’t have to choose. You can create and maintain monitoring assets using whatever method: through the API for initial creation or large-scale updates, or with the UI for point edits and customization. For example, teams that manage their detectors via Terraform can preview alerts in the UI before they actually trigger, add runbook URLs, etc. using the UI.
Get started today by signing up for a free trial of SignalFx Infrastructure Monitoring. Learn more about SignalFx Terraform Provider and SignalFx APIs. Additionally, there are many ways you can access SignalFx resources via APIs including SignalFlow or community-driven projects such as Nike’s signal_analog or Yelp’s SignalForm.
Join Splunk’s Cory Watson and HashiCorp’s Michelle Greer in a webinar to learn even more about Terraform Cloud, what’s new in Terraform 0.13, and best practices for Observability as Code. Register for "Observability-As-Code With Terraform and Splunk" today to save your spot. We look forward to seeing you there.
----------------------------------------------------
Thanks!
Amit Sharma

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2025 Splunk LLC All rights reserved.
