
The State of Observability
Realize 2.67x returns on investments. See how in our latest State of Observability report.

The AI Assistant in Observability Cloud (the “AI Assistant”, in private preview1) provides a natural language interface for observability data sources and workflows. SignalFlow is the core analytics engine in Splunk Observability Cloud, as well as a programming language and library, designed for real-time data processing and analysis of metrics. It enables users to express computations that can be applied to large volumes of incoming data streams and generate insights in the forms of metrics, charts, and detectors. In an accompanying blog post, we have provided an overview of the AI Assistant's design and architecture, in particular how we adapted the agent pattern to the observability domain. This blog focuses specifically on the challenges and methodologies involved in using large language models (LLMs) to generate SignalFlow programs.
SignalFlow grammar is modeled on Python grammar, and includes some built-in functions for data retrieval, output, and alerting. To start, we’ll look at a simple example SignalFlow program:
data('cpu.utilization',
filter=filter('host','example-host')).mean(over='5m').publish()This program first retrieves a filtered set of data points for the “cpu.utilization” metric so that only data points where the dimension “host” is equal to “example-host” are included in the computation. Next, the program computes the mean of the data points in the stream, calculating the average over 5-minute rolling windows. The publish block instructs the analytics system to output the result. Note that function calling and method chaining work similarly to how they do in Python.
Among problems in generative AI, code generation is particularly difficult because even a single incorrect character can cause a syntax error. Generation for a niche language like SignalFlow poses an even greater challenge because very few models (open or closed-source) have any knowledge of SignalFlow, or their knowledge of SignalFlow can be diluted by information about Python. Therefore, even a model fine-tuned to generate code would require significant further customization to produce high-quality SignalFlow.
Methods for tailoring an LLM's generation towards a specific task rely on augmenting the model with additional examples, typically in the form of input-output (e.g., question-answer, sentence-translation) pairs. Prompting involves describing the general relationship between input and output, and perhaps including a few examples. Retrieval augmented generation (RAG) is a refinement wherein the provided examples depend on the input. A common implementation involves performing a semantic similarity search using the user’s prompt against a data source, then including the most relevant retrieved examples in the prompt. This approach enhances the model’s responses by providing contextually relevant information. Fine-tuning goes even further by training the model on the additional examples, adjusting its internal weights and making it more proficient at the desired task. While RAG can be computationally expensive due to the increased number of input tokens (the examples are added into the prompt), fine-tuning requires a significant initial effort but offers long-term benefits by embedding the task-specific knowledge within the model itself. Both RAG and fine-tuning demand a large and diverse set of high-quality examples.
To translate user questions about their environments (e.g., “What’s the average CPU utilization for example-host over the past 5 minutes?”), our first goal was to curate a dataset with pairs of English questions and associated SignalFlow programs. This was achieved via a multi-step process indicated in the following diagram: data collection and preprocessing, SignalFlow decomposition, generating task instructions and questions, quality scoring, and producing final question-answer pairs.
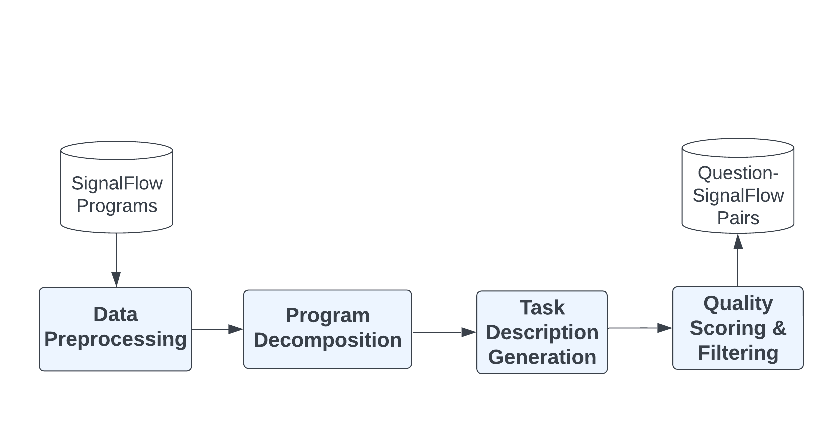
Fig 1: Data Curation Steps
Altogether, this procedure resulted in a curated dataset consisting of tens of thousands of examples, where each example consists of a casual question, a detailed task instruction, and a SignalFlow program.
Building the natural language to SignalFlow model requires some scaffolding around the dataset we have just constructed. This scaffolding consists essentially of prompting for the agent (“sub-LLM”) responsible for SignalFlow generation, a mechanism for retrieving customer-specific metrics and metadata, and program validation (including use of error messages in the event validation fails). In the current implementation, the dataset enters the agent’s workflow via RAG.
Given an incoming user question, the orchestrator LLM will determine whether a metrics query is needed to provide an answer (which is the case if the user doesn’t provide a metric name). It obtains the metric names and their metadata by calling the appropriate tools. This requires extracting search terms from the user’s question. It then passes the initial user question, the metric name(s) and metric metadata to the SignalFlow generation sub-LLM. The workflow is depicted below.
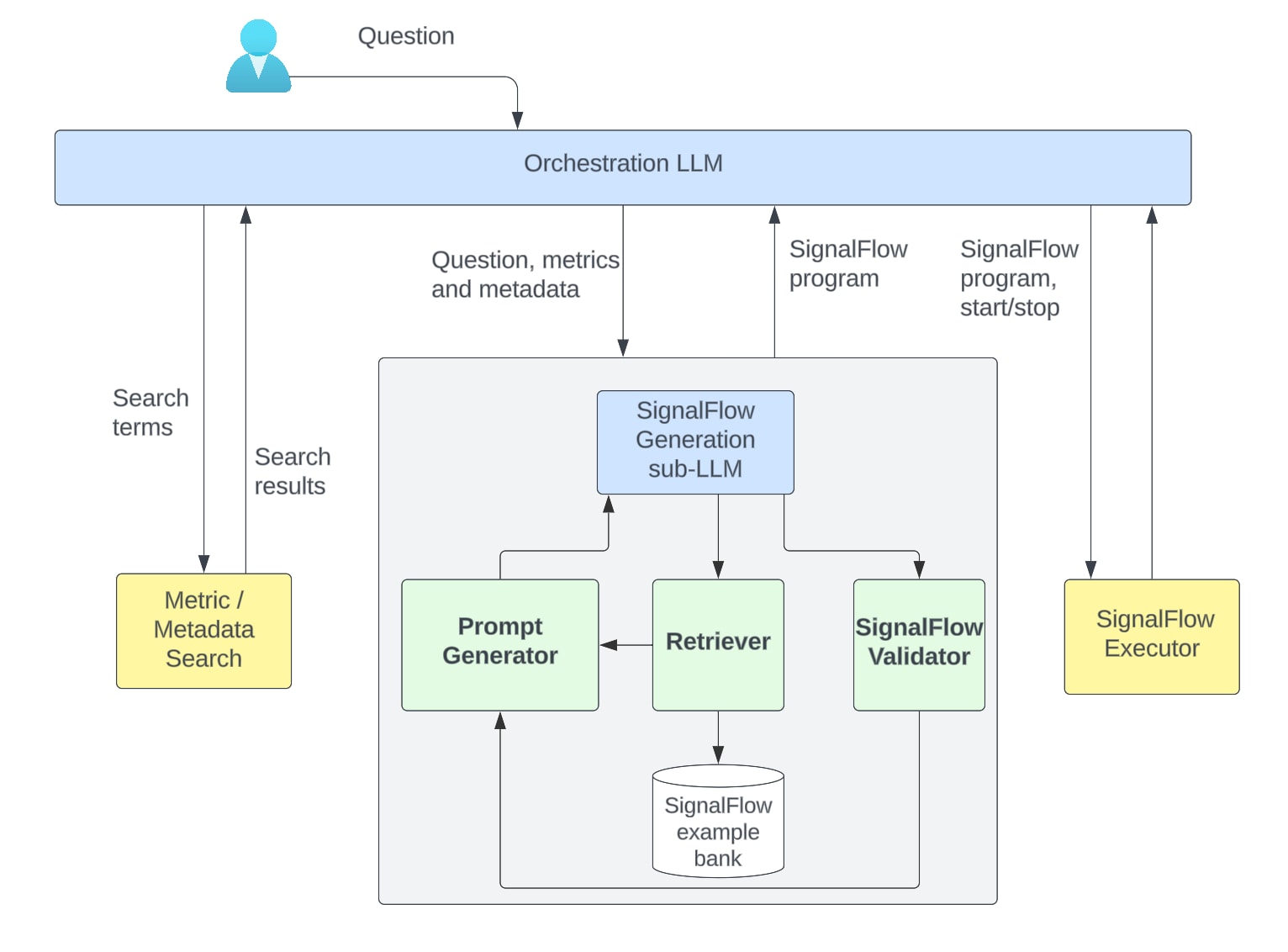
Figure 2: Overall framework of our SignalFlow generation process
The SignalFlow generation sub-LLM coordinates all steps involved in generating SignalFlow programs from questions. Its signature is to take a natural language question and some metadata context, and produce a fully formed SignalFlow program to answer the question (using the provided metadata context in the program if necessary). Its system prompt includes descriptions and examples of important SignalFlow concepts and constructions. Its main components are as follows:
Evaluating the correctness of a generated SignalFlow program is difficult since there may be multiple correct answers (programs) for a given question. Therefore, we use several evaluation metrics to get an overall picture of the performance of the sub-LLM.
Across these metrics, our sub-LLM based approach surpasses mainstream SignalFlow-capable models by a large margin. In addition, our approach excels at generating SignalFlow programs with consistently high syntax quality (with an over 99% validation success rate across 1000 programs), thanks to the syntax validation feedback loop. This empirical testing aligns with our internal anecdotal evidence as well, as we have seen multiple examples of the AI Assistant generating correct SignalFlow of moderate complexity, while other LLM-based chatbots were unable to provide useful assistance.
Building a generative AI capable of writing SignalFlow programs has required technical progress along various dimensions: curating high-quality question-program pairs, ensuring semantic and syntactic correctness in generated code with RAG and validation tools, and creating semi-automated evaluation tools. Through the SignalFlow generation sub-LLM, we have both advanced the capabilities of the AI Assistant in Observability Cloud, and also laid a foundation for future enhancements. Looking ahead, we aim to explore ways to enhance the SignalFlow generation capabilities via advanced RAG techniques, improved evaluation pipelines, and user feedback integration.
Splunk’s position at the forefront of observability technology provides a solid platform for these advancements, promising ongoing innovation and improved user experiences in monitoring and analytics. Moving forward, we will continue to refine the AI Assistant, driven by customer feedback and evolving technologies. The AI Assistant in Observability Cloud is currently in private preview and available to select preview participants, so sign up today!
1 The AI Assistant in Observability Cloud is currently available to selected private preview participants upon Splunk's prior approval.
2 The “self-reflection” capabilities of LLMs are still being studied and debated. There are some papers, such as Reflexion: Language Agents with Verbal Reinforcement Learning and Large Language Models Can Self-Improve that support the idea of self-reflection. Without supporting either side of the debate, we chose to have an LLM score and filter out its own generations because we empirically found that our follow-up manual curation efforts to label generated data as high quality were aided by the self-reflection we had the LLM perform. For our specific task of generating a dataset of English question and SignalFlow program pairs, this was a convenient way to filter out generated pairs, not justify the inclusion of other pairs within our dataset.
This blog was co-authored by:
With special thanks to contributors:


The world’s leading organizations rely on Splunk, a Cisco company, to continuously strengthen digital resilience with our unified security and observability platform, powered by industry-leading AI.
Our customers trust Splunk’s award-winning security and observability solutions to secure and improve the reliability of their complex digital environments, at any scale.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2025 Splunk LLC All rights reserved.
