We think these will be most relevant to you
We think this fits your needs best. Want to see it in action?
OBSERVABILITY
Splunk Observability
Find and fix problems faster, ensure reliability and get control over your data and costs.

Differentiators
Improve your digital resilience by building a leading observability practice
Unify visibility
Only Splunk provides ITOps and engineering with shared data, context and workflows for complete digital visibility.
Accelerate troubleshooting
Splunk helps ITOps and engineering teams accurately diagnose problems across any environment and spend less time in war rooms.
Control data and costs
Splunk allows for data flexibility and lets you instrument everything while you only pay for what you need.

products
Splunk Observability
Splunk Observability Cloud
Deliver high performing applications and better customer experiences with unified metrics, traces and logs.

Splunk IT Service Intelligence
Ensure service performance with full visibility, AIOps and incident intelligence.
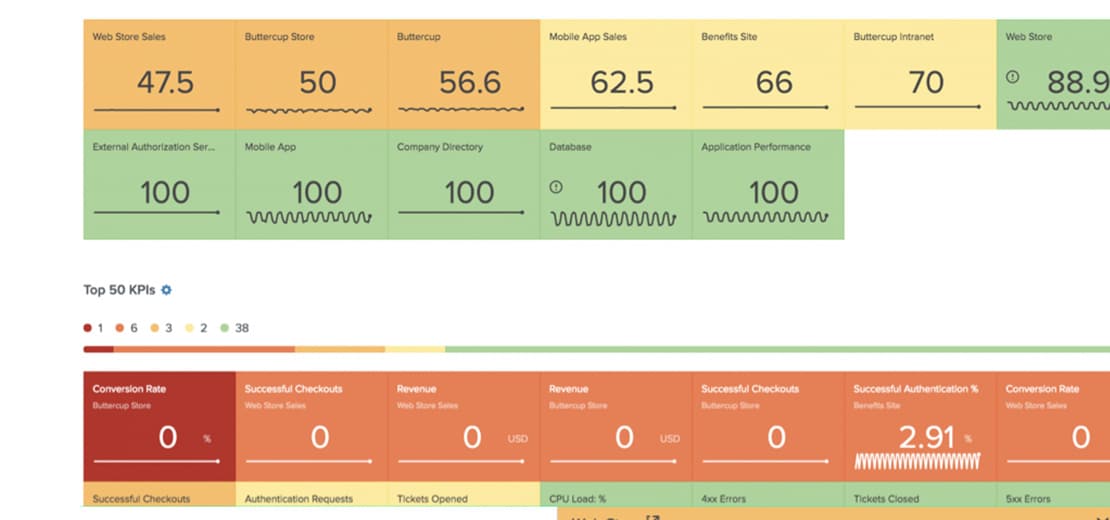
Splunk AppDynamics
Optimize hybrid and on-prem application performance with full-stack observability linked to business performance.
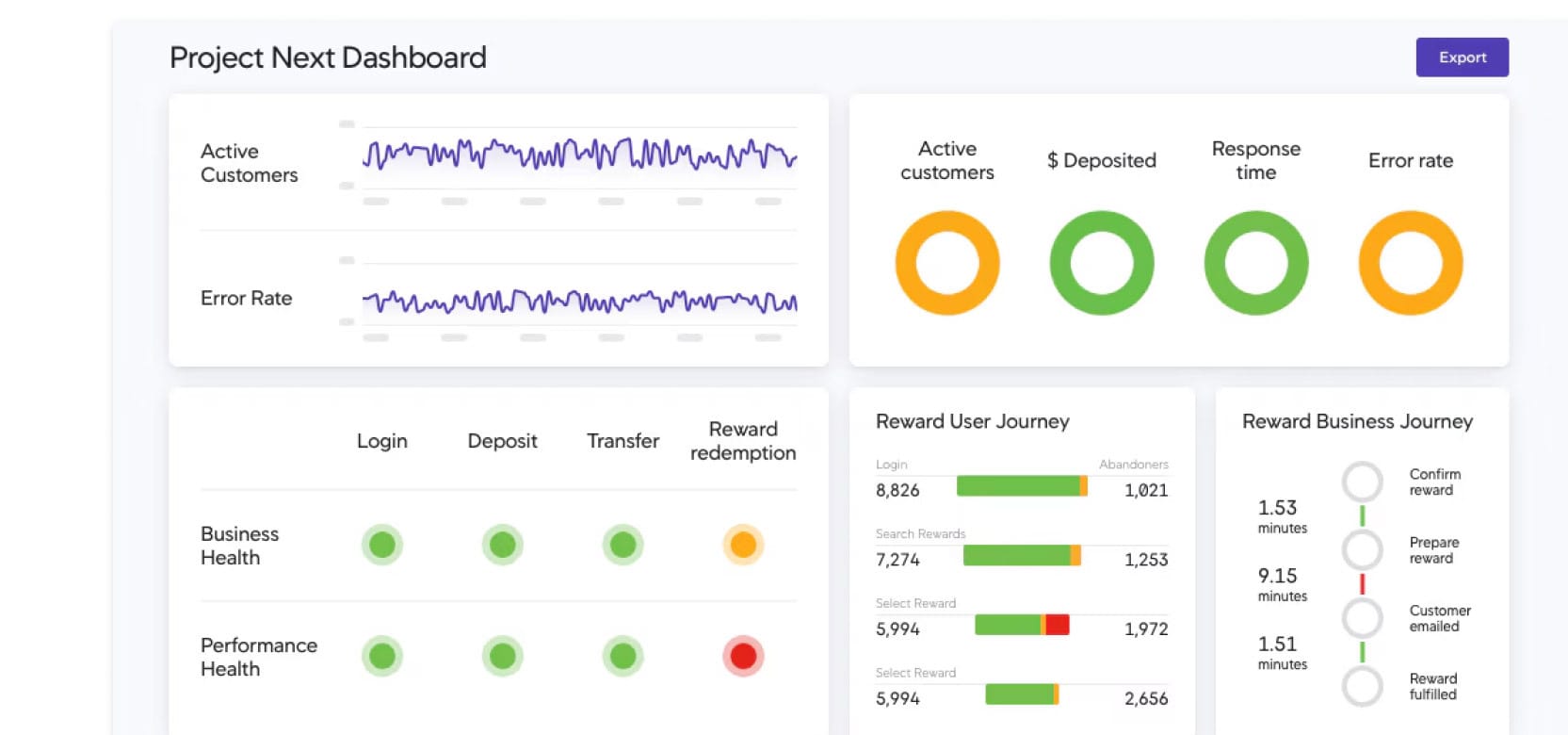

Are you a current Observability Cloud customer looking for learning resources?
Check out our Observability Learning Path on Splunk Community, with curated content organized by skill level.
The Splunk Advantage
Integrated with Splunk Cloud Platform

All your logs in context

Collect Telemetry Data in Any Format

Related categories
Security
Modernize your security operations and protect your business with data, analytics, automation and end-to-end integrations.
Platform
The extensible Splunk data platform for the hybrid cloud powers unified security, full-stack observability and limitless custom applications.


Infrastructure Monitoring
Real-time infrastructure monitoring and troubleshooting for all environments.
Splunk Cloud
Search, analyze, visualize and act on your data with a flexible and cost-effective data platform service.
